| Image may be NSFW. Clik here to view.  |
| VANET system modeled in Zhang et al. |
| Image may be NSFW. Clik here to view.  |
| The Agent/Environment Loop in Reinforcement Learning |
The two entities involved in the Reinforcement Learning loop are the agent and the environment. The agent is the process by which some system makes decisions, not necessarily the system itself. For example, when we refer to the agent when speaking about a floor cleaning robot we don't mean the physical, mechanical form of the robot. The agent refers to the software making the decisions for any path planning or battery state of health for said robot. The environment is the "place" where its state has some probability of change due to any actions the agent takes in it. For the purposes of the floor cleaning robot this would typically be the room it's supposed to clean. In the paper we will discuss the environment is the network of vehicles through which it's planning optimal network paths.
The environment has some set of states S. The agent has access to some set of actions, A, and can take an action a ∈ A at time t, aₜ, in the environment. At the time the agent takes this action, the environment is in its current state, sₜ∈ S. Once the action is executed in the environment, there is a probability of transition to a new state, sₜ₊₁. The key to Reinforcement Learning is the reward function. Once that transition from sₜ to sₜ₊₁ takes place, the environment should emit some reward rₜ.
As the agent explores the environment the agent should, over time, learn the dynamics of the system. We represent these dynamics as a Markov Decision Process (MDP). As the agent learns an ever-increasing representative MDP for the environment, it learns when to exploit beneficial states and when to explore new unexplored states to increase its total expected reward in the environment. Learning this balance between exploration and exploitation of the states is known as the agent's policy and the hope is that the agent will, over time, converge onto an optimal policy. Once this happens, the agent should know which action to take in a given state to effect optimal performance in the environment. Or in the words of the greatest band of all time:
| Image may be NSFW. Clik here to view.  |
| The Q-learning equation broken down to its constituent parts |
The authors employ the use of Q-learning based neural networks for their proposed method. The above image shows the Q-learning algorithm's Q equation, which is used to calculate a currently optimal State-Action selection policy for all future states starting at the current state. You can see from its form that Qⁿᵉʷ is derived arithmetically over Q(sₜ, aₜ) (the current state) and the maximum Q the agent has learned from the future state (maxQ(sₜ₊₁, a)). This recursive nature points to the Q function's place among the Bellman equations, which are key to numerous approaches in artificial intelligence, optimization and dynamic programming. They pop up everywhere. Additionally, there are two hyper-parameters available to configure. The learning rate, α (note that this is the greek alpha), controls the velocity of the change in the gradient descent during back propagation in the neural network. The discount factor, γ, introduces exponential decay on the future value estimates. This allows for preferring delayed (for smaller decay) or immediate (for larger decay) reward.
Essentially, a Q-learning agent learns a table with states and actions on the axes, with each "cell" containing the maximum reward returned in a given state and the action that earned it. However, calculating over a table in large state spaces quickly becomes inefficient so we turn toward function approximation to alleviate the table problem using a neural network as the function approximator (actually it's two neural networks but I will leave that for the reader to delve into).

Ok. So that was a really quick and dirty intro into RL, Q-learning, and Deep RL. Now we can turn our attention toward A Deep Reinforcement Learning-based Trust Management Scheme for Software-defined Vehicular Networks. In it, Zhang et al. propose a dueling deep reinforcement learning network architecture to evaluate trust in nodes in a vehicular ad hoc network (VANET). A VANET is a network of vehicles operating in the same environment providing vehicle-to-vehicle and vehicle-to-ground-station data communications and are key to intelligent transportation systems (ITS) and autonomous vehicles. Each vehicle and ground station in a VANET is a node in a dynamic network that grows and shrinks as more vehicles enter or leave the network or as the network leaves the service area of a given ground station. The dynamic nature of VANETs leaves it vulnerable to nodes exhibiting malicious behavior through bad quality of service in which they fail to forward packets. Since these malicious nodes reduce the VANET's quality of service through degradation of performance, the network should be routed such that packets avoid as many intermediate malicious nodes along the routing path as possible. The authors propose training and deploying a deep learning network architecture as an agent for a VANET as a SDN to provide this trust-based routing control.
| Image may be NSFW. Clik here to view.  |
| VANET system modeled in Zhang et. al |
The VANET is modeled as a 12 vehicle VANET environment shown in the image above. They hold the node population static so as to avoid dynamic sizing of the malicious population and allow nodes to change state between good and malicious performance. Each vehicle connects to its neighbor or a ground station to communicate information on its speed, direction, and trust. Malicious nodes will drop information passed to it, so the network needs to route around them as much as possible to maintain good quality of service by selecting the most trusted neighbor at each hop.

Image may be NSFW. Clik here to view.  |
| T-DDRL network architecture from Zhang et al. |
The Trust-based Dual Deep Reinforcement (T-DDRL) Learning framework proposed by Zhang et al.
The T-DDRL relies on the trust information of a node as its reward function and is modeled by the node's forwarding ratio. Computing trustworthiness for any pair of vehicles <i, j> at time t is defined as Vᵢⱼ(t):

The forwarding ratio, for example, for the control routing information direct trust VTᵢⱼᶜ⁽ᵗ⁾, is calculated according to the interaction between two neighbor vehicles:

(5) is simply the ratio between the total number of packets sent between vehicle i and j and the number of packets forwarded to the next hop by vehicle j all in the same time-step t. The ratio is similarly computed for the data packet direct trust VTᵢⱼᴰ⁽ᵗ⁾. These ratios are used as the immediate reward (the reward at time t) for all links in the network including the current vehicles i and j through the path from source to sink, assuming optimal trust information for all future links.
| Image may be NSFW. Clik here to view.  |
| Figure 4: Convergence performance vs. differing architectures of DQN |
Clik here to view.

Figures 4 and 5 show the learning performance of a neural network with varying layers and a dueling neural network with varying learning rates, respectively. Figure 4 shows that the 9 layer network configuration reaches convergence fastest vs. 7 and 8 layers. Figure 5 shows that convergence is detrimentally impacted by increasing learning rates. These results were used for hyper-parameter tuning for a final architecture configuration.
| Image may be NSFW. Clik here to view. 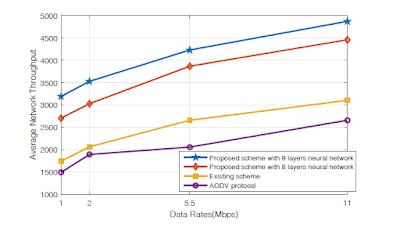 |
| Figure 6: Average network throughput vs. differing data rates |
| Image may be NSFW. Clik here to view.  |
| Figure 7: Average end-to-end delay vs. differing number of vehicles |
In conclusion, we went over several things in this post; we reviewed my prior post Evaluating Trust in User-Data Networks: What Can We Learn from Waze? which introduced the idea of trust metrics and various prior-work on evaluating agent trust and data, I introduced the concepts of VANETs, Reinforcement Learning, Q-learning, and Deep Reinforcement Learning to present some background information needed for the paper we reviewed, and finally we reviewed said paper A Deep Reinforcement Learning-based Trust Management Scheme for Software-defined Vehicular Networks by Zhang et al. Zhang et al. shows us that a trust-defined reward function paired with deep reinforcement learning is a viable method for intelligent autonomous decision-making in a system. However, their proposed solution is based on a predefined trust metric. Pairing a system like their T-DDRL system with one that provides predicted trust observations that don't require pre-definition would allow for the implementation of end-to-end, trust-based decision making with generality respective to the trust metric involved. In a future post, we will investigate some ideas on how to achieve such a system.
Sources
Mnih, V., Kavukcuoglu, K., Silver, D. et al. Human-level control through deep reinforcement learning. Nature 518, 529–533 (2015). DOI:https://doi.org/10.1038/nature14236
Dajun Zhang, F. Richard Yu, Ruizhe Yang, and Helen Tang. 2018. A Deep Reinforcement Learning-based Trust Management Scheme for Software-defined Vehicular Networks. In Proceedings of the 8th ACM Symposium on Design and Analysis of Intelligent Vehicular Networks and Applications (DIVANet'18). Association for Computing Machinery, New York, NY, USA, 1–7. DOI:https://doi.org/10.1145/3272036.3272037